Apache Kafka Developers training- module 1
I’m preparing the Kafka Developer Certification, so taking Confluent training Confluent Developer Skills for Building Apache Kafka. To me, I write notes down for they’re a useful resource, so if when I want to refresh my memory on Kafka topic that I learnt, I can go here to review. In the meanwhile, it gives me a motivation to record this developer training.
This training consists of 12 modules, so this post is notes of the first module I started for this training.
- Introduction
- Fundamentals of Apache Kafka
1. Introduction
Course Intro (skipped)
General training outlines:
- - Write
ProducersandConsumersto send data to and read data from Kafka - - Integrate Kafka with external systems using
Kafka Connect - - Write streaming applications with
Kafka Streams & ksqlDB - - Integrate a Kafka client application with
Confluent Cloud
2. Fundamentals of Apache Kafka
2.1 Fundamentals of Apache Kafka - 1 of 2
Kafka, a Distributed Streaming Platform, is a data architecture for data distributing, storage and processing. It is used for building real-time data pipelines and streaming apps, its main characteristics are horizontally scalable, fault-tolerant, wicked fast in production.
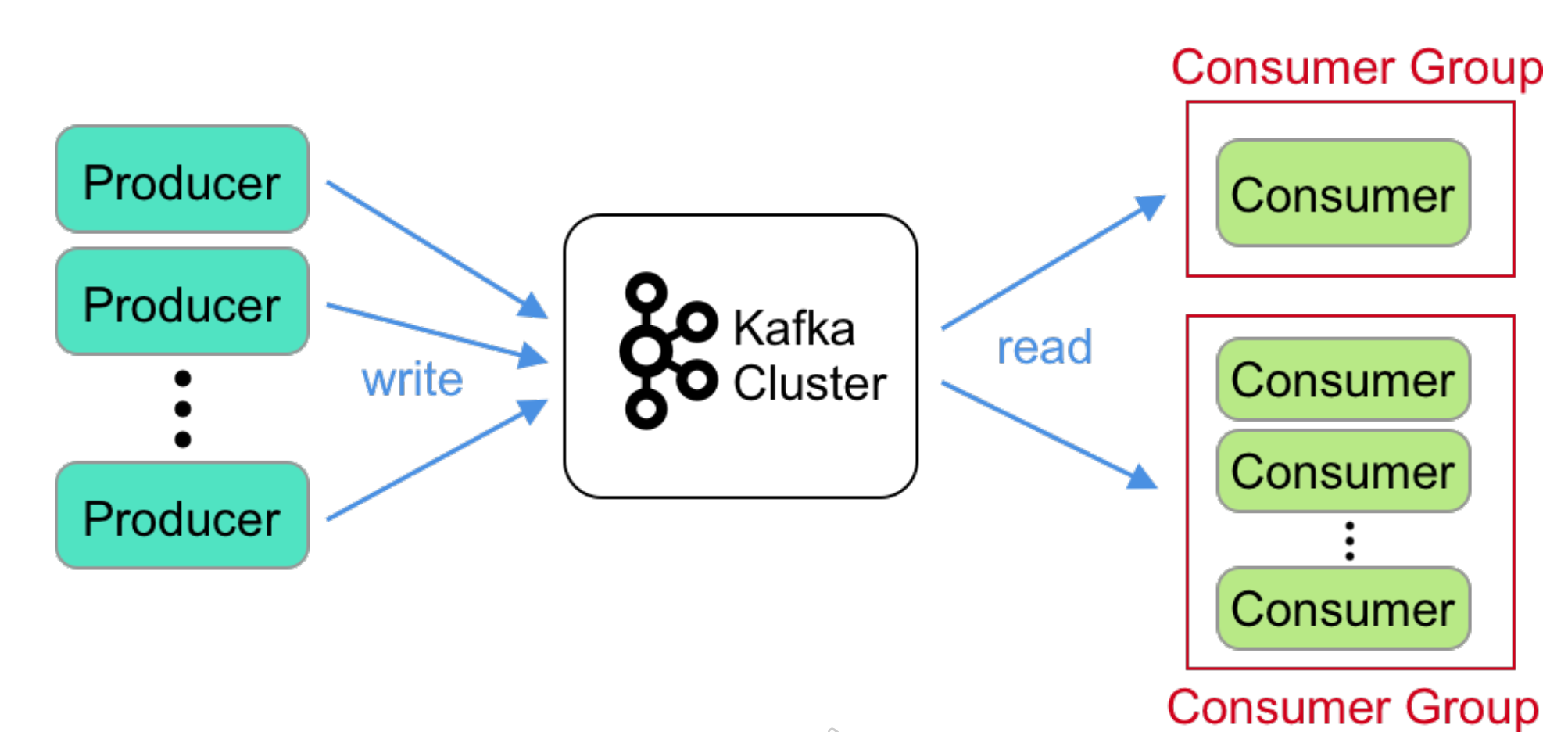
Kafka Client (API)
From its built-in API, we can directly use high level code to send() and subscribe() data. Producer to write data to one or many topics,
Consumer (Groups) to subscribe data.
(*Kafka cluster: cluster of brokers, store events.)
Data Structure => Log
The immutable, append only, and once written, they are never changed data structure. Elements that are added to the log are strictly ordered in time.
Policy
They have two ways to retain messages, the default is retention policy, another one is by key, named compact policy.
- retention policy
- compact policy
#For example, if use case that is mutable state data, data can be modified, deleted or updated,
#Kafka only need the most recent messages, then `compact policy` is an option.
*Log compaction is a granular retention mechanism that retains the last update for each key. A log compacted topic log contains a full snapshot of final record values for every record key not just the recently changed keys.
*Brokers, Topics, Partitions, and Segments
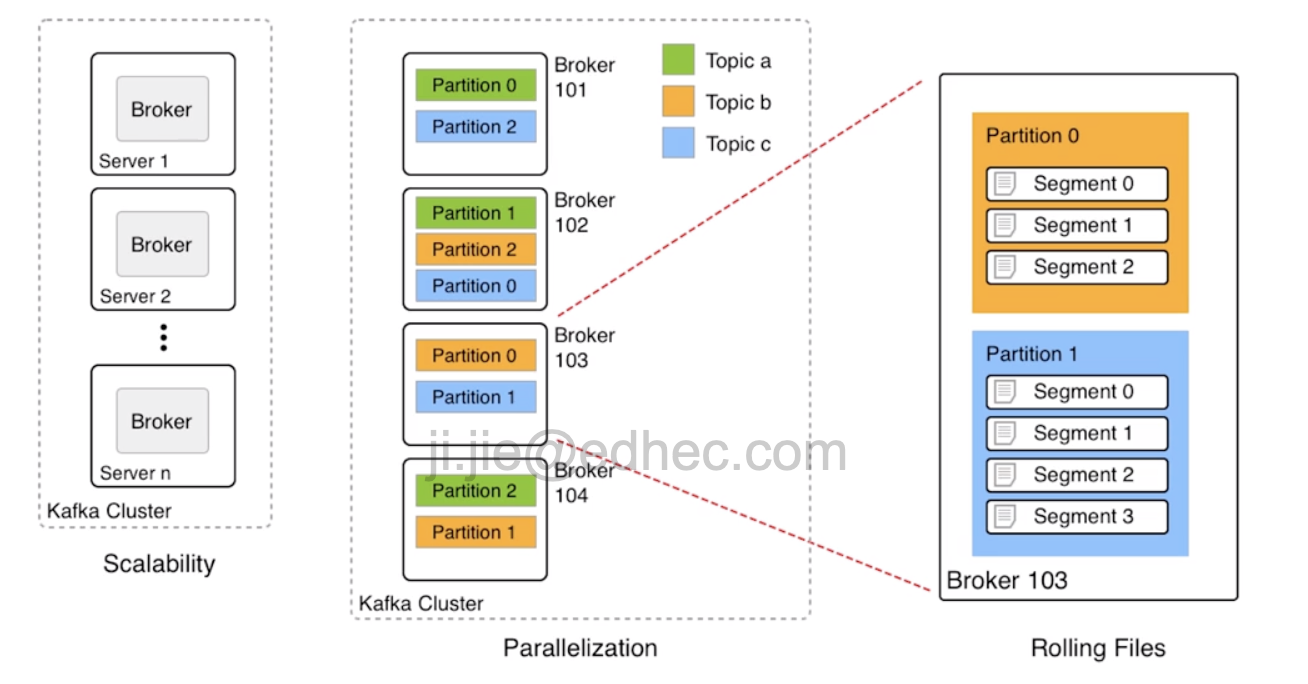
- - Broker: think it as VM, which provides you memory, storage etc.
- - Topic: comprises all messages to a given category.
- - Partition: split a single topic into many partitions to parallelize work. The default algorithm for partition is
hash code of the message key. - - Segment: a single log file, or commit log.
- - Replica: *replica of each partition is always store in different brokers, to produces high availability of data
Replication
To keep around more than one copy of the log for reliability. This process is called replication. Replication and partitioning are two core concepts in distributed system,
In any distributed system, high availability (HA) through *replication*; scalability through *partitioning*.
One possible way of doing a log replication is to define a (single) leader and a number of followers. The leader writes and keeps the principal copy of the log. The followers read from the leader’s log (managed by the leader) and update their own local log accordingly.
Adjust the parameter replica.lag.time.max.ms to change the default lag time.
Only the leader writes data originating from a data source to the log. The followers only ever
read from the leader.
The followers whose log is up to date with the leader are called in-sync replicas. Any of those followers can take over the role of a leader if the current leader fails.
Data elements
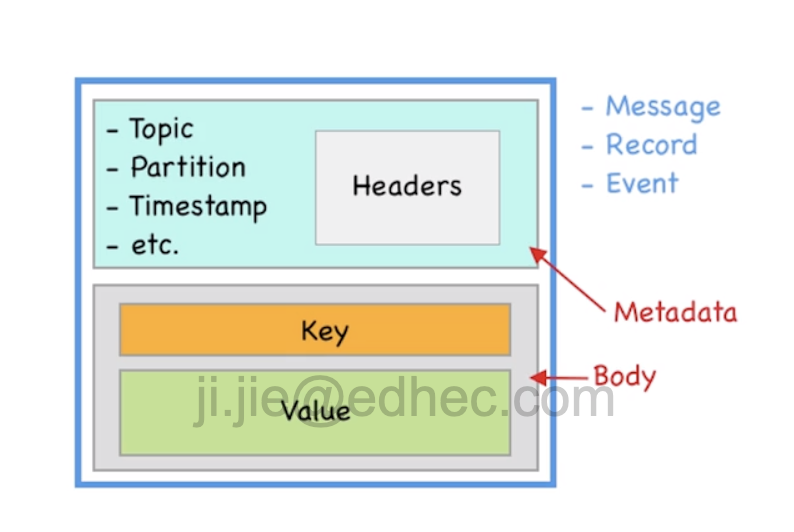
A record in Kafka consists of Metadata and a Body. The metadata contains offset, compression, magic byte, timestamp etc, Body part is <key, value>,
value part is usually containing the business relevant data,
key by default is used to decide into which partition a record is written to. Identical key of records go into
the same partition, it also provides ordering in partition level.
Kafka Connect
Kafka Connect is a standard framework for source and sink connectors. It makes it easy to import data from and export data to standard data sources such as relational DBs, HDFS, cloud based blob storage, etc. It is a data integration tool for connecting with external systems.
2.2 Fundamentals of Apache Kafka - 2 of 2
High Level Architecture of Kafka Producer
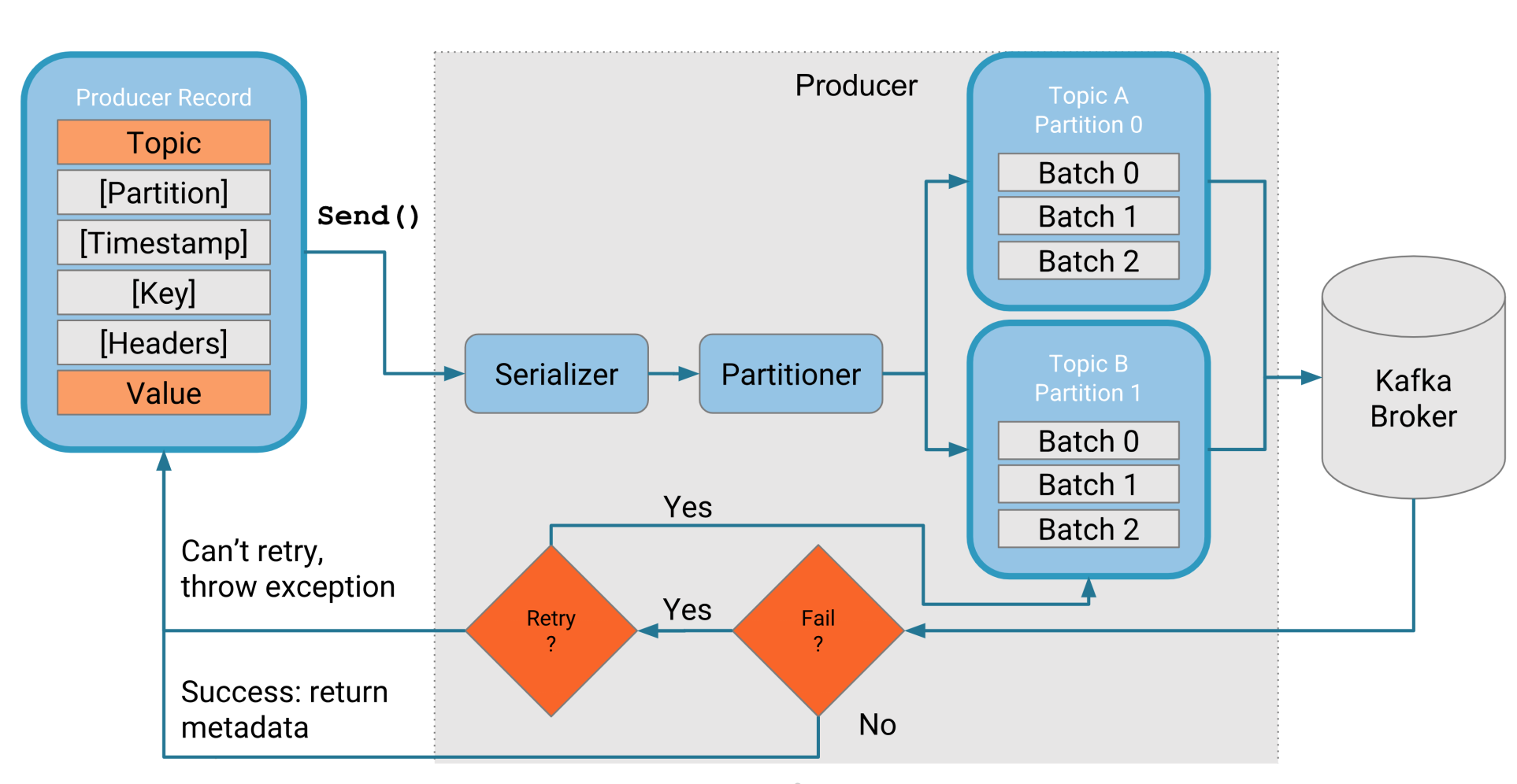
Serializer
Kafka doesn’t care about what you send to it as long as it’s been converted to byte stream beforehand. That is also the format Kafka stores data in broker, the binary, it can store any format data, to keep Producer and Consumer communicate through this data format, but independently. So make sure the connection between Producer and Consumer clients, use serialization and deserialization to convert bytes to high-level data format.
In practice, message before send() to broker, should pass Interceptor, Serializer, Partitioner.
Batching
Batching happens on a per topic partition level (for batch only happens in partition level, only messages written to the same partition are batched together).
Producer API write batch to Kafka Broker, by using either ACK or NACK.
- - If
ACKthenall is goodand success metadata is returned to the producer - - If
NACKthen the producer transparently retries until themax number of retriesis reached, in which case an exception is returned to the producer
Partitioning
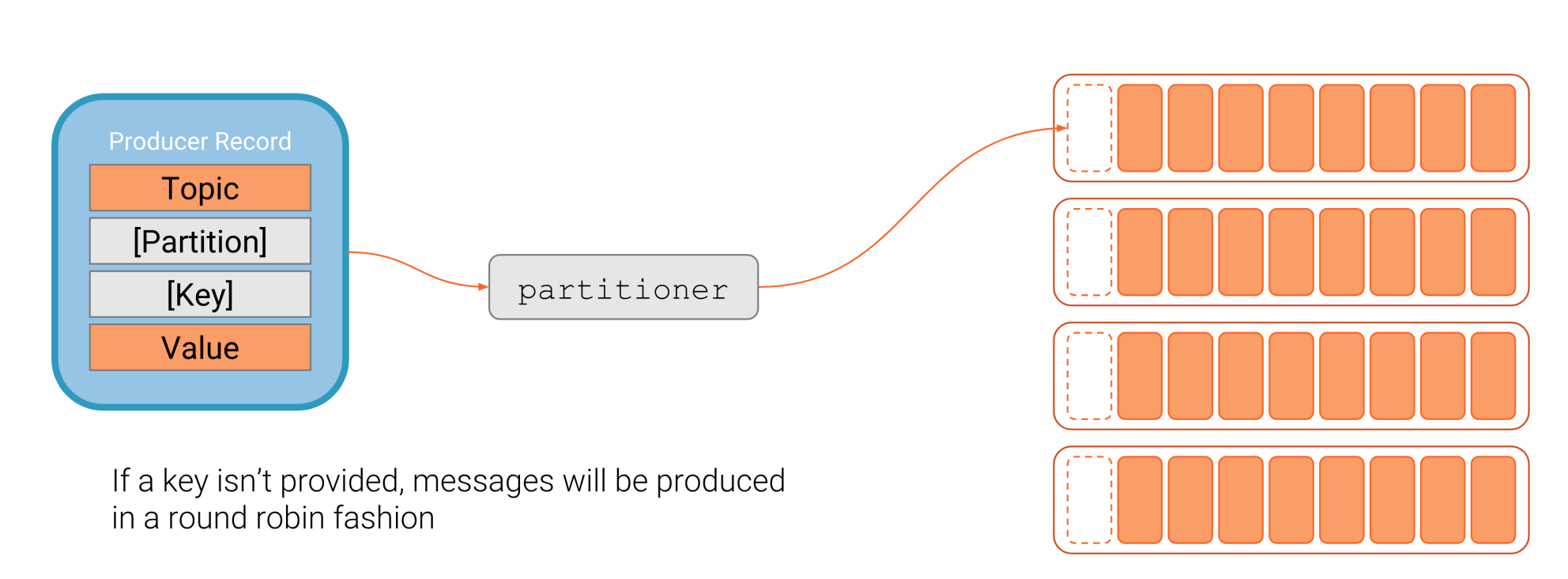
How to calculate partitions? => partition= hash(key) % numPartitions
if key is not provided, then partition will be done in round robin basis.
Key Cardinality
For key based partitioning, it will have key skew etc, so will cause key cardinality, which affects the amount of work done by the individual consumers in a group. So poor key choice can lead to uneven workloads.
Consumer Group
First why need Consumer Group? => high throughput, we are using distributed system now. For single consumer will consume all the records form partitions, use multiply consumers will run assigned partitions at the same time.
*note: multiple consumer groups can consume from the same topic(s), that means consumers can be as many as user wants; each consumer in a group can be assigned zero, one, or many partitions, but will not assign the same partition to more than one consumer in the same group at the same time, so if number of (consumer > partitions), then the extra consumer will be idle.
Questions?
a. Explain the relationship between topics and partitions?
=> Topics are logical containers in Kafka and (usually) contain records or data of same type.
Partitions are used to parallelized work with topics. Thus one topic has 1…n partitions
b. How does Kafka achieve high availability?
=> Kafka uses replication to achieve HA. Each partition of a topic is available in the cluster on
say 3 distinct brokers. In case of failure of one broker, still two additional copies of the
data are available.
c. What is the easiest way to integrate your RDBMS with Kafka?
=> By using Kafka Connect with a plugin/connector that suits your needs, e.g. a JDBC source
or sink connector, depending of the direction the data has to flow.
2.3 Lab - Using Kafka’s Command-Line Tools
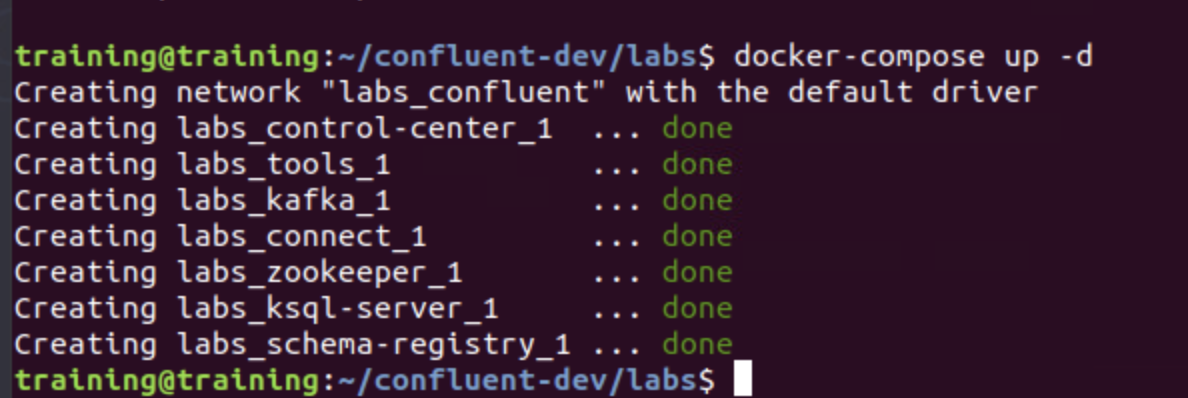
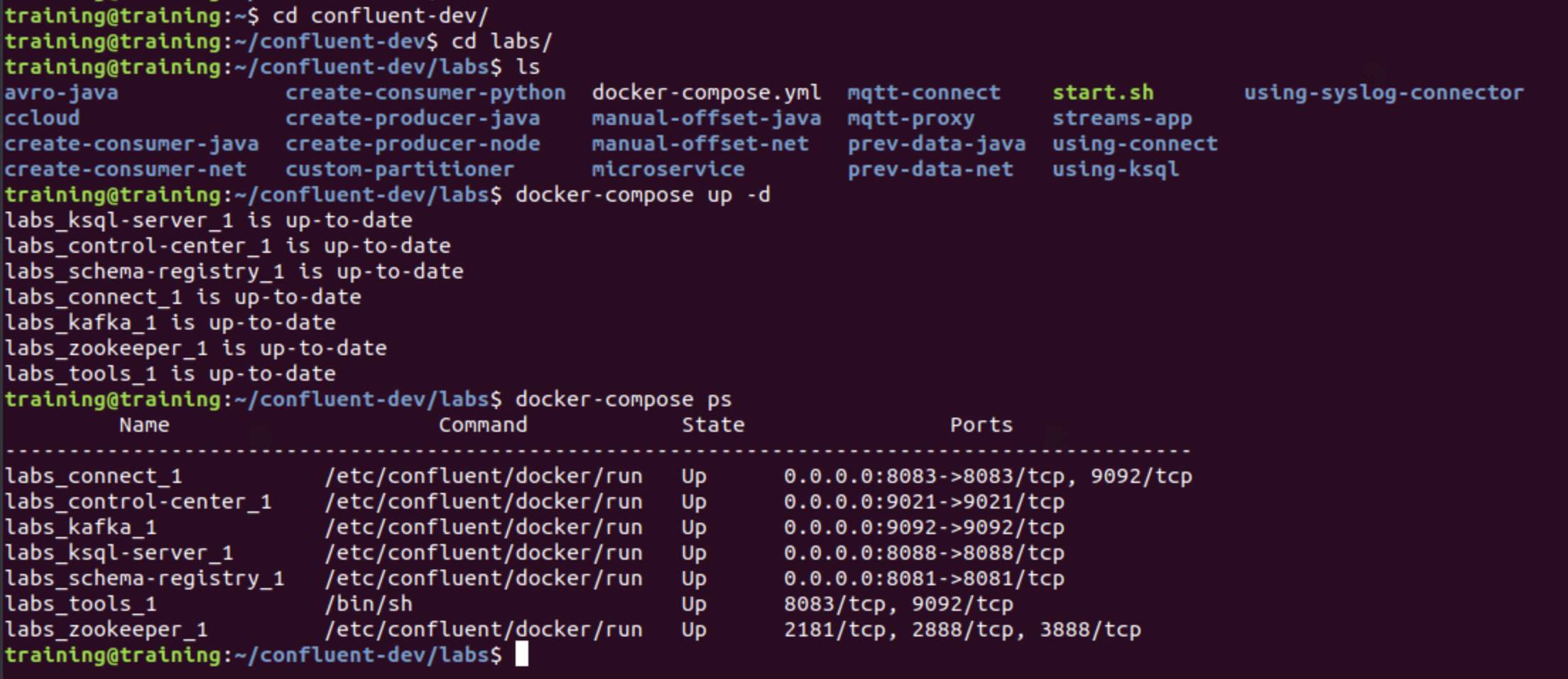
cd ~/confluent-dev/labs
docker-compose up -d
docker-compose ps
Run Kafka Cluster and Confluent Control Center
Check if all services are up and running
Use built-in CLI
produce message and read message use command line, the basic of Kafka I have already done in the beginning of this year, but let me go through again to follow this training in a more correct way. The new part I learnt is, the default Producer and Consumer are based on null keys, but can add arguments to read by keys.
Create topics and config such as partitions, replications
kafka-topics --bootstrap-server kafka:9092 \
--create \
--partitions 1 \
--replication-factor 1 \
--topic testing
Producer
kafka-console-producer \
--broker-list kafka:9092 \
--topic testing
--property parse.key=true \
--property key.separator=,
Consumer
kafka-console-consumer \
--bootstrap-server kafka:9092 \
--from-beginning \
--topic testing
--property print.key=true
Cleanup your environment
docker-compose down -v