How to use Kafka for ETL
I choose to use Apache Kafka, one of the reasons is it provides API for user-friendly Python which easy to integrate to many other tools via Kafka Connect, also it’s so sophisticated for big data integration. I had confusion when I tested with both database connector through Python code and Kafka Connect. The Kafka Connect one is hard for the first time setting up and requires strict schema registry, otherwise it broke the ‘contract’ between schema reads and writes that Producer and Consumer requests. Though Python DB Connect and Kafka Connect both work, but I have one friend, who taught me few big data cases last year suggested me, Kafka Connect is industrial usage, which can make life easier. So I will demonstrate both approaches for streaming integration.
- Connect with SQL db
- Use Kafka Connect (Debezium CDC and JDBC connector for data ingestion)
Besides since KSQL was released on last November. I haven’t heard it before and it’s more for another topic on Kafka processing layer, same as Kafka Stream, so I exclused the details and implementations on this exploratory article.
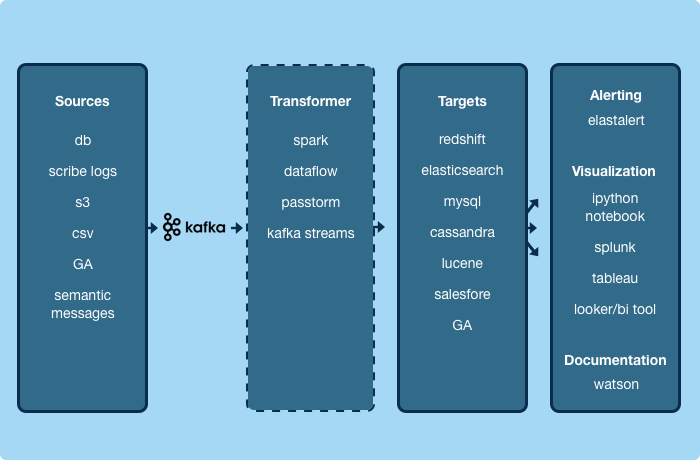
In general, the key to solve the problem is to frame it correctly, same to learning a new tool, is to understand the diagram of this tool well.
So what is Kafka?
there are tons of articles of high quality on Confluent blog and Kafka official website and its documentation, so I won’t explain here, for as a programmer one key skillset is to know how to read source and documentation. For anything you can learn is available on the Internet now, the doorway is Google. Let me just highlight key components that on this diagram, then we get our hands dirty.
- Kafka Broker, Topic, Message, Partition, Producer, Consumer, Offset.
- Zookeeper use for consumer leader selection.
- Avro, use this schema to communicate through Kafka, producer encode the schema and consumer decode, Kafka provides REST API to update schema.
- Kafka Connect (pulled from Debezium), is a framework for ingesting data with Kafka, used as source and sink.
Some basics need to understand
- Log compaction, well-covered by Jay Kreps link
spoiler alert: if you want find the truth, go for the log. - Throughput, default mode is asynchronous/non-blocking writes increase number of partitions to scale consumers.
- Exactly once semantic, here is one article link wrote about the processing guarantee in Kafka by comparing this semantic with no guarantee, most once, effectively once.
- Data retention policy to decide how long the data can be stored in broker.
- CDC (change data capture), monitor the changes (insert, update and delete). Similar to RDBMS's trigger.
Additions:
The usage with Redis Cache: for data that is frequently needed or retrieved by APP users, a cache would be served as a temporary data store for quick and fast retrieval without any need for extra database round trips. Note that data stored in a cache is usually data from an earlier query or copy of data stored somewhere else. This feature is vital because the more data we can fetch from a cache, the faster and more efficiently system performs.
Hand dirty time:
Set up
#Install Zookeeper
$ brew install zookeeper
$ brew services start zookeeper
or
$ bin/zookeeper-server-start.sh config/zookeeper.properties
$ kafka-server-start /usr/local/etc/kafka/server.properties
# kafka default is running on the port 9092, the zookeeper is on 2181
$ config/server.properties
#set up multi-broker cluster
$ cp config/server.properties config/server-1.properties
$ cp config/server.properties config/server-2.properties
# edit on server-1.properties, for eaxmaple
config/server-1.properties:
broker.id=1
listeners=PLAINTEXT://:9093
log.dirs=/tmp/kafka-logs-1
Next step is install Kafka, download from its official website, after config, run Kafka before execute Producer and Consumer
$ kafka-server-start /usr/local/etc/kafka/server.properties
Update You will see something runs like below.
[2020-02-18 05:24:19,405] INFO Kafka version: 5.3.2-ce (org.apache.kafka.common.utils.AppInfoParser)
[2020-02-18 05:24:19,405] INFO Kafka commitId: 231a0ebf45e66e60 (org.apache.kafka.common.utils.AppInfoParser)
[2020-02-18 05:24:19,405] INFO Kafka startTimeMs: 1581974659405 (org.apache.kafka.common.utils.AppInfoParser)
[2020-02-18 05:24:19,436] INFO [Producer clientId=producer-1] Cluster ID: SvQw5uyQQfO-Y7ZPCVn7Kw (org.apache.kafka.clients.Metadata)
[2020-02-18 05:24:19,473] INFO [Producer clientId=producer-1] Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms. (org.apache.kafka.clients.producer.KafkaProducer)
[2020-02-18 05:24:19,478] INFO Successfully submitted metrics to Kafka topic __confluent.support.metrics (io.confluent.support.metrics.submitters.KafkaSubmitter)
[2020-02-18 05:24:21,390] INFO Successfully submitted metrics to Confluent via secure endpoint (io.confluent.support.metrics.submitters.ConfluentSubmitter)
[2020-02-18 05:24:29,373] INFO [GroupCoordinator 0]: Member consumer-1-ebd32b86-8edf-4d22-8e0e-f94d85ef93e9 in group console-consumer-41220 has failed, removing it from the group (kafka.coordinator.group.GroupCoordinator)
[2020-02-18 05:24:29,379] INFO [GroupCoordinator 0]: Preparing to rebalance group console-consumer-41220 in state PreparingRebalance with old generation 5 (__consumer_offsets-0) (reason: removing member consumer-1-ebd32b86-8edf-4d22-8e0e-f94d85ef93e9 on heartbeat expiration) (kafka.coordinator.group.GroupCoordinator)
[2020-02-18 05:24:29,384] INFO [GroupCoordinator 0]: Group console-consumer-41220 with generation 6 is now empty (__consumer_offsets-0) (kafka.coordinator.group.GroupCoordinator)
[2020-02-18 05:24:29,397] INFO [Log partition=__consumer_offsets-0, dir=/usr/local/var/lib/kafka-logs] Rolled new log segment at offset 5 in 5 ms. (kafka.log.Log)
[2020-02-18 05:24:48,190] INFO [Log partition=kafkatesting-0, dir=/usr/local/var/lib/kafka-logs] Found deletable segments with base offsets [0] due to retention time 604800000ms breach (kafka.log.Log)
[2020-02-18 05:24:48,191] INFO [Log partition=kafkatesting-0, dir=/usr/local/var/lib/kafka-logs] Rolled new log segment at offset 470 in 2 ms. (kafka.log.Log)
[2020-02-18 05:24:48,192] INFO [Log partition=kafkatesting-0, dir=/usr/local/var/lib/kafka-logs] Scheduling log segment [baseOffset 0, size 38425] for deletion. (kafka.log.Log)
[2020-02-18 05:24:48,193] INFO [MergedLog partition=kafkatesting-0, dir=/usr/local/var/lib/kafka-logs] Incrementing merged log start offset to 470 (kafka.log.MergedLog)
[2020-02-18 05:24:48,194] INFO [Log partition=kafkatesting-0, dir=/usr/local/var/lib/kafka-logs] Incrementing log start offset to 470 (kafka.log.Log)
[2020-02-18 05:25:33,503] INFO [Log partition=__consumer_offsets-0, dir=/usr/local/var/lib/kafka-logs] Deleting segment 0 (kafka.log.Log)
[2020-02-18 05:25:33,511] INFO Deleted log /usr/local/var/lib/kafka-logs/__consumer_offsets-0/00000000000000000000.log.deleted. (kafka.log.LogSegment)
[2020-02-18 05:25:33,518] INFO Deleted offset index /usr/local/var/lib/kafka-logs/__consumer_offsets-0/00000000000000000000.index.deleted. (kafka.log.LogSegment)
Set up multiple partitions
$ bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor <number-of-replicas> --partitions <number-of-partitions> --topic <topicName>
$ kafka-topics --zookeeper <host>:2181 --create --topic <topicName> --partitions <number-of-partitions> --replication-factor <number-of-replicas>(old way)
Add partitions
$ bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic <topicName> --partitions 3
Create topic
$ kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions <1> --topic <topicName>
Check existed topics
$ bin/kafka-topics.sh --zookeeper localhost:2181 --list
Describe a topic
$ bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic <topicName>
$ bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic <topicName>(old way)
Check consumer group information
$ kafka-consumer-groups --bootstrap-server localhost:9092 --list
$ kafka-consumer-groups --bootstrap-server localhost:9092 --describe --group <groupName>
Delete topic, make sure topic default setting is delete.topic.enable= True
$ bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic <topicName>
Config retention times
$ bin/kafka-configs.sh --zookeeper localhost:2181 --alter --entity-type topics --entity-name test_topic --add-config retention.ms=1000
$ bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic mytopic --config retention.ms=1000 (old way)
Publish message to Kafka
$ cd kafka_2.11-1.1.0
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic <topicName>
Consume message from Kafka
$ kafka-console-consumer --bootstrap-server localhost:9092 --topic <topicName> --from-beginning
Get consumer offset for Topic
$ bin/kafka-consumer-offset-checker.sh --zookeeper=localhost:2181 --topic=<topicName> --group=<groupName>
Reset offset
$ kafka-consumer-groups.bat --bootstrap-server kafka-host:9092 --group
<groupName> --reset-offsets --to-earliest --all-topics --execute
$ kafka-consumer-groups.bat --bootstrap-server kafka-host:9092 --group
<groupName> --reset-offsets --to-earliest --topic <topicName> --execute
$ kafka-consumer-groups.bat --bootstrap-server kafka-host:9092 --group
<groupName> --reset-offsets --to-offset <offsetNumber> --to-earliest --topic <topicName> --execute
Install avro, understand how to use Python and REST
$ pip install confluent-kafka[avro]
$ kafka-configs --zookeeper localhost:2181 --entity-type topics --entity-name _schemas --describe Configs for topic '_schemas' are cleanup.policy=compact
# SCHEMA_REGISTRY_URL
# subject-value
# schemaId
Implementation
Produce message
- config broker, ports, zookeeper connection, default topic, producer timeout, encoder, partition, retentation time, etc
- write avro schema with REST
- implement with python code
# how to know the consumer lag? consumer_offsets (group, topic, partition number)
kafka-console-consumer --consumer.config /tmp/consumer.config \
--formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" \
--zookeeper localhost:2181 \
--topic __consumer_offsets
Read message
- set offset, consumer timeout, etc
- implement with python code
Connect data to RDBMS
- MysqlDB
- Kafka Connect
Advanced Kafka Development:
Create multi-thread consumer specifying offsets consumer rebalancing partitioning data message durability