Apache Kafka Developers training- module 2
The second module for Kafka Developer Training, this module is about Kafka Architecture, which focuses on configuration and strategy of partitioning and replication. For partitioning data is good for performance but not for reliability, in a distributed system, should apply partition and replica for both scalability and reliability.
3.1 Replication => reliability
Kafka provides built-in replication for replicating each partition, to maintain multiple copies of each partition.

Kafka maintains replicas of each partition on other Brokers in the cluster, so the number of replicas should be up to number of brokers, even the number of replicas is configurable. Replica is follow one leader rule, only leader can read/write, follower only need to try to keep their records same as leader => copy the data from the commit log of the leader as a pull request; they do not interact with any external clients.
Replicas exist only to provide reliability in case of Broker failure. If a leader fails, the Kafka cluster will elect a new leader from among the followers, The clients will automatically switch over to the new leader.
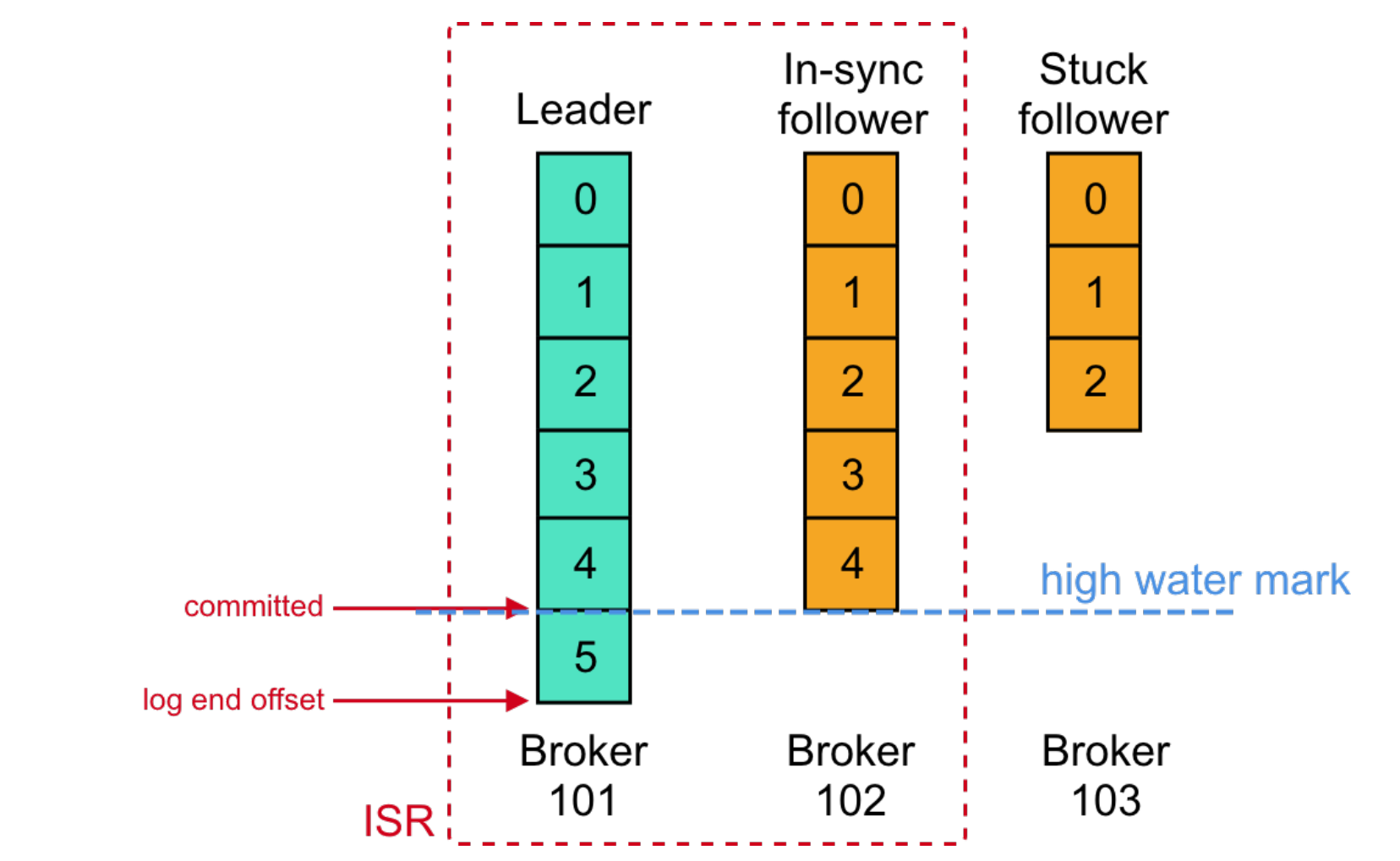
Kafka uses replication to guarantee the durability (and HA) of data, there are two kind of sync replicas, In-Sync Replicas (ISR), OSR.
- Each partition can be replicated.
- Each replica is on a different broker.
In-Sync Replicas (ISR)
The In-Sync Replicas (ISR) is a list of the replicas - both leader and followers - that are identical up to a specified point called the high-water mark.
ISR is a good candidate when the leader fails. A follower does not have to have all messages from the leader to be considered in-sync. An ISR follower is only guaranteed to have all the committed messages.
3.2 Scaling using Partitions

Each broker place leader and followers of partitions, for client Producer and Consumer, they send metadata request to broker(Controller) to get response (* here need to make sure the host of broker and client is match, especially if host on different machines). So they will be updated with metadata which broker has the leader of which partition.
Each consumer in a group can be assigned 0, one or more partitions, but each partition in group will be sign no more than one consumer in the group at the same time.
On Consumer side, message with the same key form the same producer will delivered to Consumer in order in a partition level. Kafka hash the key and map the result to specific partitions. Because of the unbounded of messages, so messaged can be consumed in combined partitions set. It’s unlikely to have orders in whole topics, but common in subtopics, to use hash key partitioning. If key is null and default Partitioner is used, the record is sent to a random Partition.
Group Consumption Balances Load
To extend the scalability, is to use Consumer Group, which is an automatic failure detection and load rebalancing. If any of consumer in the Consumer Group is failed, then the any partitions that assigned to that consumer will be reassigned to the remaining consumers in that group. (no need any manually change, Kafka will automatically change it). Even one consumer can be added in the Consumer Group, so that later can group more consumers.

To config Consumer Group, use from group.id parameters. Kafka Topics allow the same message to be consumed multiple times by different Consumer Groups.
A Consumer Group binds together multiple consumers for parallelism. Members of a Consumer Group are subscribed to the same topic(s). The partitions will be divided among the members of the Consumer Group to allow the partitions to be consumed in parallel. This is useful when processing of the consumed data is CPU intensive or the individual Consumers are network-bound.
Within a Consumer Group, a Consumer can consume from multiple Partitions, but a Partition is only assigned to one Consumer to prevent repeated data.
- 1.A single Partition is consumed by only one Consumer in any given Consumer Group
- 2.Message with the same key will go to the same Consumer(but one issue for this case, is if changing number of partitions will cause
joinproblem) - 3.
partition.assignment.strategyin the Consumer configuration
Consume Partitions
There are three built-in strategies to assign partitions.
1. Range (default)
It sends partitions to the same consumer, if more extra consumer existed, then will be idle. This is a good case when need to join, use hash key partitioning. This strategy is not evenly balanced, but do the distributed join for different topics, called co-partitioning partitions will be assigned evenly to each consumer, it can assign the different topics to the same consumers.
2. RoundRobin
It processes the records independently from different topics, s a good use case to use when no need to join.
3. Sticky
It’s similar to round robin but proposed after, used more often. It occurs in rebalancing, when one consumer in consumer group is failed, the need to reassign the partition to a new consumer, to make less changes, then use the sticky strategy.
3.3 Lab - Consume from Multiple Partitions
I moved the dev environment from Confluent provided training VM to local, for the VM has time limited and connection issue.
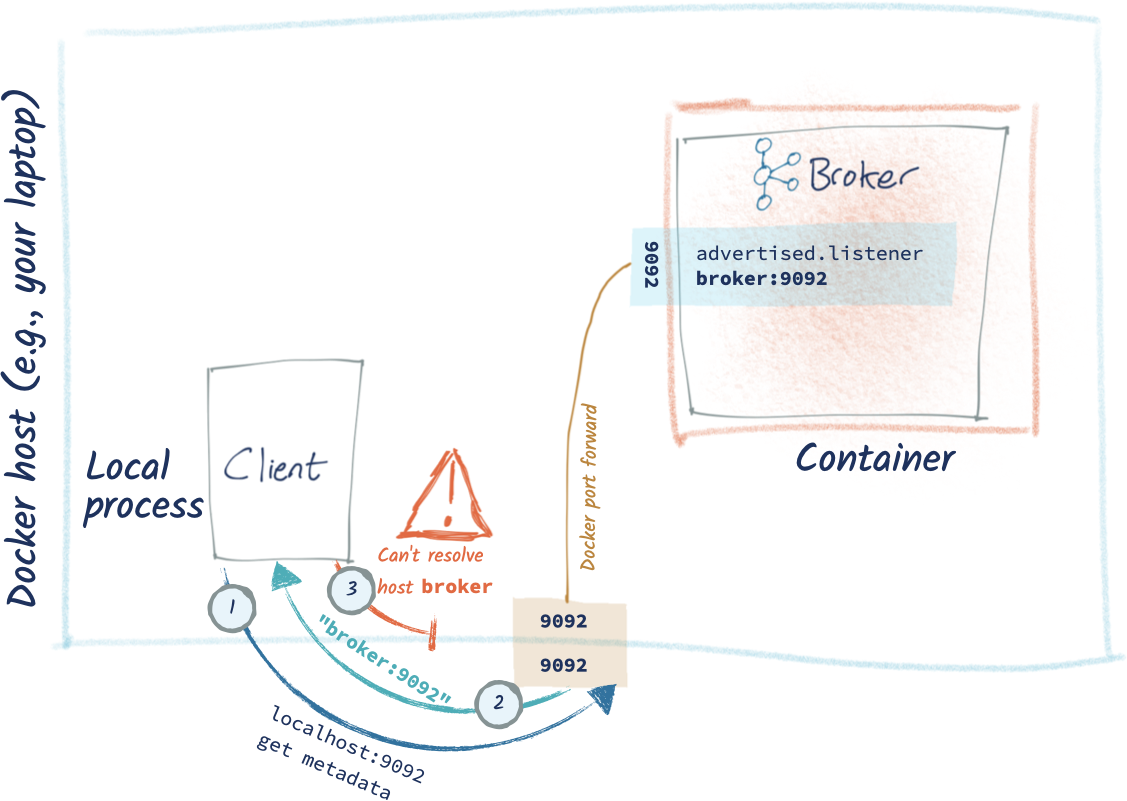
So reproduce the environment in local machine, it has one troubleshooting. Error message is WARN Couldn't resolve server kafka:9092 from bootstrap.servers as DNS resolution failed for kafka (org.apache.kafka.clients.ClientUtils),
I found an article from Robin Moffatt which has a solution and details.
If client machine host is different from broker machine, the connection is broke and returned metadata is mismatch. So change broker listener address to localhost (or optionally add more listeners in broker).
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
listeners=PLAINTEXT://0.0.0.0:9092
In more details, I use Docker to implement this training exercise, so I should use his scenario 2 and scenario 4, the container based Broker and local Client, the local is different from local. See the image below (the below image I take from his blog for illustration.)
After config on local, let’s produce and consume multiple partitions.
Create Topic with multiple partitions, for in this exercise I only have one broker configured, so only one broker available, so only can have one replication in total.

seq 1 100 > numlist && confluent-5.3.0/bin/kafka-console-producer \
--broker-list localhost:9092 \
--topic test-partitions <numlist
confluent-5.3.0/bin/kafka-console-consumer \
--bootstrap-server localhost:9092 \
--from-beginning \
--topic test-partitions
The consumer read all messages is using the default partitioning, range, so I have 4 partitions, it will evenly divided all into 4 subsets.